
Oric Lawson | Getty Images
Je ne suis pas un data scientist. Et bien que je connaisse bien le cahier Jupyter et que j’aie écrit une quantité décente de code Python, je ne dis pas que je suis proche d’un expert en apprentissage automatique. Alors quand j’ai fait Partie 1 de l’expérience d’apprentissage automatique No-Code/Low-Code Et avec un taux de précision supérieur à 90 % sur l’un des modèles, je soupçonnais que j’avais fait une erreur.
Si vous ne l’avez pas encore regardé, voici une petite revue avant de revenir aux deux premiers articles de cette série. Pour voir à quel point les outils d’apprentissage automatique ont progressé pour le reste d’entre nous – et pour me racheter La mission qui ne peut être gagnée J’ai été chargé de l’apprentissage automatique l’année dernière – j’ai pris un ensemble de données sur les crises cardiaques branlantes d’une archive de l’UC-Irvine et j’ai essayé de déjouer les étudiants en sciences des données avec les outils à faible code « easy button » d’Amazon Web Services et sans code.
Tout l’intérêt de cette expérience était de voir :
- Si un novice peut utiliser ces outils de manière efficace et précise
- Si les outils étaient plus rentables que de trouver quelqu’un qui savait ce qu’il faisait et de le lui confier
Ce n’est pas exactement une image fidèle de la façon dont les projets d’apprentissage automatique se déroulent habituellement. Et comme je l’ai trouvé, l’option « sans code » fournie par Amazon Web Services –Toile SageMaker—Il vise à travailler en tandem avec une approche plus axée sur la science des données SageMakerStudio. Mais Canvas a surpassé ce que j’ai pu faire en utilisant l’approche Low Coding de Studio – bien que cela puisse être dû à mes mains moins habiles avec le traitement des données.
(Pour ceux qui n’ont pas lu les deux articles précédents, il est maintenant temps de rattraper : C’est la première partieEt le Voici la deuxième partie.)
Évaluation du travail du robot
Canvas m’a permis d’exporter un lien partageable qui a ouvert le formulaire que j’ai créé avec ma structure complète de plus de 590 lignes de données de patients de la Cleveland Clinic et de l’Institut hongrois de cardiologie. Ce lien m’a donné un peu plus d’informations sur ce qui s’est passé à l’intérieur de la boîte très noire de Canvas avec Studio, un basé sur l’acheteur Une plate-forme pour mener des expériences de science des données et d’apprentissage automatique.
Comme son nom l’indique, Jupyter est basé sur Python. Il s’agit d’une interface Web vers un environnement de conteneur qui vous permet de faire pivoter le noyau en fonction de différentes applications Python, en fonction de la tâche.
Exemples des différents conteneurs de noyau disponibles dans Studio.
Les noyaux peuvent être remplis avec tous les modules dont le projet a besoin lorsque vous effectuez des explorations axées sur le code, telles que la bibliothèque d’analyse de données Python (Panda) et SciKit-Learn (sklearn). J’ai utilisé une version sur site de Jupyter Lab pour effectuer la plupart des analyses de données brutes afin d’économiser le temps de calcul d’AWS.
L’environnement Studio créé avec le lien Canvas comprenait du contenu prédéfini qui donnait un aperçu du modèle produit à partir de Canvas – dont je discute brièvement dans dernier article:

Certains détails comprenaient les hyperparamètres utilisés par la meilleure version du modèle créé par Canvas :
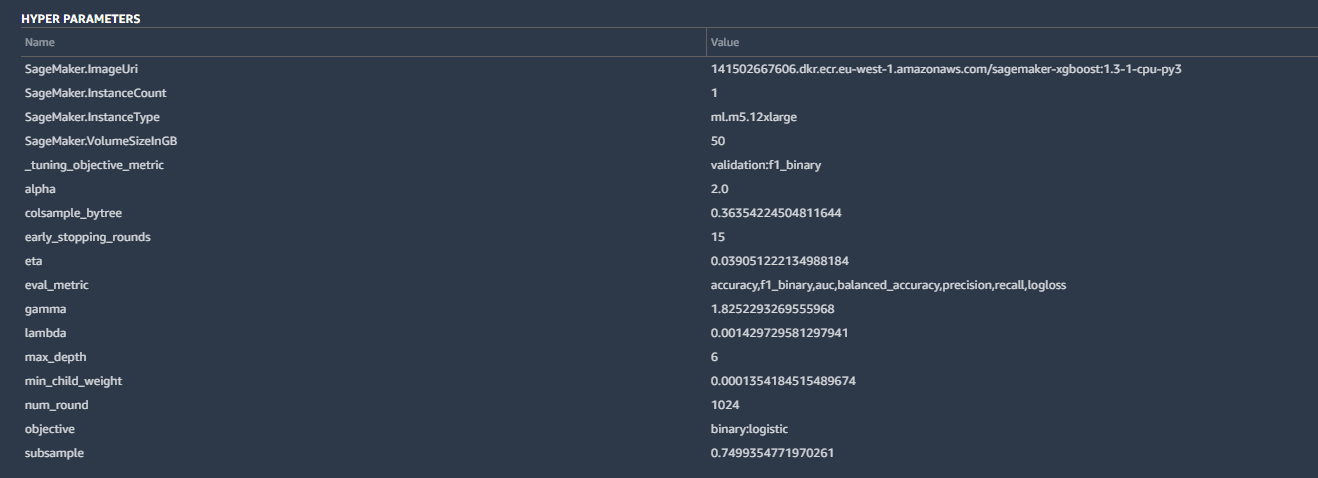
Les hyperparamètres sont des modifications qu’AutoML apporte aux calculs par l’algorithme pour améliorer la précision, ainsi que certaines opérations de base : paramètres d’instance SageMaker, échelle de synthèse (« F1, dont nous parlerons plus tard ») et autres entrées. critères standard pour une classification binaire comme la nôtre.
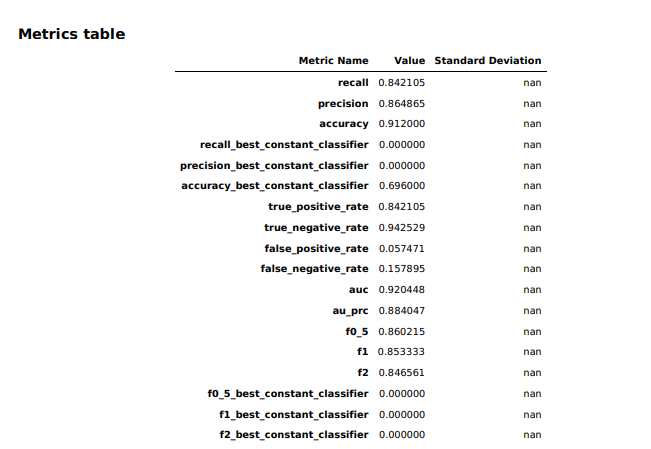
La vue d’ensemble du modèle dans Studio a fourni des informations de base sur le modèle produit par Canvas, y compris l’algorithme utilisé (XGBoost) et l’importance relative de chacune des colonnes étiquetées avec quelque chose appelé Valeurs SHAP. SHAP est un acronyme vraiment choquant qui signifie « SHapley Additive exPlanations », qui est la théorie des jeuxUne méthode basée sur l’extraction de la contribution de chaque caractéristique de données à la modification de la sortie du modèle. Il s’avère que la « fréquence cardiaque maximale » a eu peu d’effet sur le modèle, alors que la thalassémie (« thall ») et les résultats angiographiques (« caa ») – les points de données pour lesquels nous avons des données manquantes – ont eu plus d’impact que je ne l’aurais souhaité. Je ne pouvais tout simplement pas les faire tomber, semble-t-il. J’ai donc téléchargé un rapport sur les performances du formulaire pour obtenir des informations plus détaillées sur la manière de différer le formulaire :

« Music lover. Gamer. Alcoholist. Professional reader. Web specialist. »